小红书开源 FireRedASR 语音识别模型:中英文方言歌词全能识别
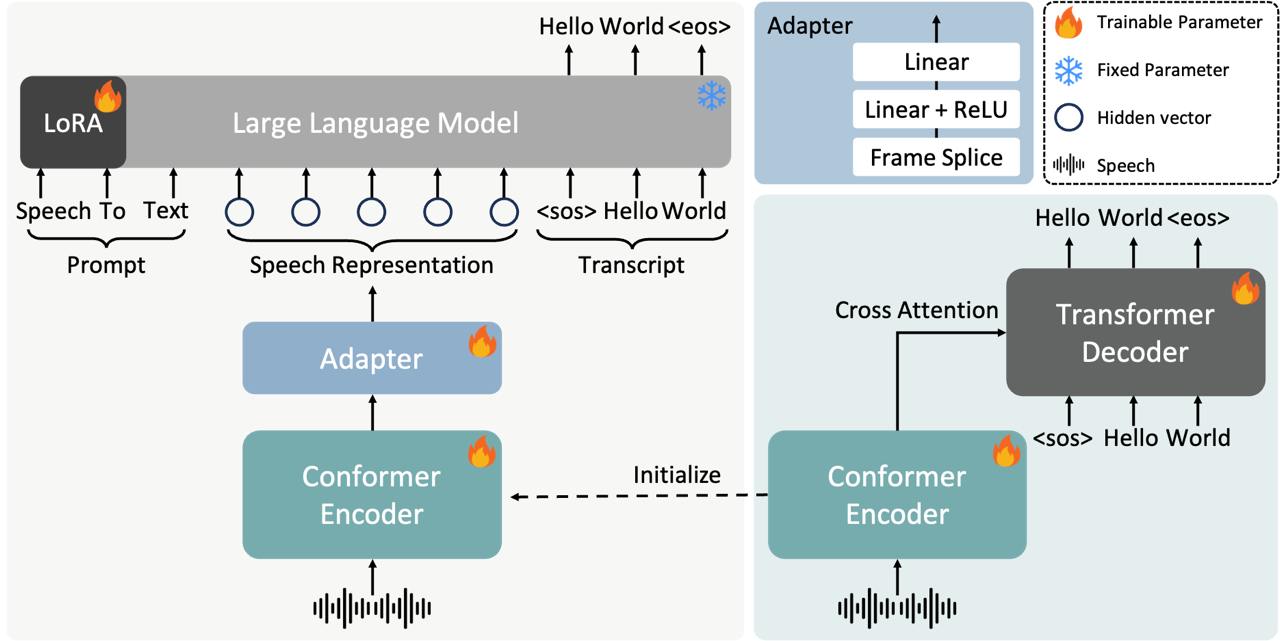
近日,小红书正式开源了其最新的语音识别模型 FireRedASR,这一模型在语音识别领域展现了卓越的性能,尤其是在中英文混合识别、方言处理以及歌词识别等复杂场景中表现尤为突出。FireRedASR 在公共普通话 ASR 基准测试中取得了新的最佳成绩,标志着语音识别技术的一次重要突破。
FireRedASR 的核心优势
FireRedASR 提供了两种不同的架构设计,分别针对高性能和高效率的场景需求。首先是 LLM 版,该版本拥有高达 8.3B 参数,能够实现极高的识别准确率,特别适合需要高质量语音转写的场景。LLM 版支持无缝的端到端语音交互,能够处理复杂的语音输入,例如中英文混合对话、方言识别以及歌词转写等任务。
另一种是 AED 版,该版本参数规模为 1.1B,在性能和效率之间实现了良好的平衡。AED 版更适合普通应用场景,例如日常语音助手、实时语音转写等,能够在保证较高识别准确率的同时,显著降低计算资源消耗。
技术亮点与应用场景
FireRedASR 的推出不仅提升了语音识别的准确率,还扩展了其应用场景。无论是需要高精度的专业语音转写,还是对实时性要求较高的普通应用,FireRedASR 都能提供出色的解决方案。例如,在音乐领域,FireRedASR 能够准确识别歌词中的复杂发音,甚至包括方言和外语混合的内容;在智能助手领域,它能够实现流畅的中英文混合对话,为用户提供更自然的交互体验。
此外,FireRedASR 的开源也为开发者社区提供了强大的工具。开发者可以通过 GitHub 获取模型的完整代码和预训练权重,快速集成到自己的项目中。项目地址为:FireRedASR GitHub。
未来展望
随着语音识别技术的不断发展,FireRedASR 的推出无疑为行业树立了新的标杆。其开源策略不仅推动了技术的普及,也为更多创新应用提供了可能性。未来,我们可以期待更多基于 FireRedASR 的语音交互产品和服务,进一步改变人们的生活方式。

如果你对语音识别技术感兴趣,或者正在寻找一款高性能的语音转写工具,不妨尝试 FireRedASR,体验其强大的功能和卓越的性能。